OpenRefine 
Objetivo
Utilizar OpenRefine para administrar, validar y limpiar de manera eficiente datos sobre biodiversidad, asegurando una mejor calidad para su publicación.
Introducción
Sobre la Herramienta
OpenRefine es un software creado con el objetivo de pulir datos crudos hasta convertirlos en diamantes ![]() , los cuales son activos valiosos en la era del BigData.
, los cuales son activos valiosos en la era del BigData.
Este sofware permite visualizar y manipular datos tabulares, facilitando el mejoramiento de la calidad general de un conjunto de datos. Tiene la apariencia de un software tradicional de hoja de cálculo (similar a Excel), pero funciona como una base de datos. Esto significa que OpenRefine no es adecuado para adicionar nuevas filas de datos, pero es extremadamente poderoso cuando se trata de explorar, limpiar y vincular datos.
OpenRefine es un software de código abierto bajo una licencia BSD y se instala localmente, por lo que funciona como una aplicación web personal y de acceso privado a la que se accede desde un navegador web.
Esta herramienta sirve para todo tipo de datos. Sin embargo, en este laboratorio se explica su funcionamiento en el contexto de datos sobre biodiversidad, estandarizados en Darwin Core. Puede consultar mayor información de la herramienta en el manual de usuario (en inglés).
Convenciones
- Los elementos del estándar Darwin Core aparecen en color verde y cursiva. Por ejemplo: occurrenceID.
- Los archivos a utilizar en los ejercicios se muestran entre comillas angulares, negrita, y tienen una tipografía diferente. Por ejemplo: «archivo_Ejemplo.xls».
- Las secciones, ventanas y componentes de las herramientas utilizadas se muestran entre comillas inglesas y en negrita. Por ejemplo: “Create Project”.
- Las opciones de las herramientas que se asocian a instrucciones (dar clic, seleccionar, etc.) aparecen en formato de código, con una tipografía distinta de color naranja. Por ejemplo:
Choose Files. - Las secuencias de instrucciones y pasos se muestran en formato de código y negrita, con una tipografía distinta de color naranja. Por ejemplo:
Paso 1 > Paso 2. - Las líneas que se escriben directamente en las herramientas, para programar o realizar algún proceso en específico, aparecen en formato de código, con una tipografía distinta de color negro. Por ejemplo:
línea_de_prueba.
Requerimientos
- Navegador Chrome instalado y configurado como navegador predeterminado.
No utilice Internet Explorer para este laboratorio, ya que OpenRefine no funciona bien en este navegador.
Archivo de trabajo
- Descargue el archivo «datos_Estructurados.xlsx» para realizar el laboratorio.
Paso 1 - Instalación
Instalación en Windows
- Descargue «OpenRefine versión 3.4.1 + Java para Windows».
- Descomprima el archivo descargado y copie la carpeta resultante en el disco local (C:/).
- Abra la carpeta y haga doble clic en [«openrefine.exe»].
- Aparecerá una ventana de comando (que no debe cerrar) e inmediatamente después su navegador web mostrará una nueva ventana con la aplicación.
Instalación en Mac
- Descargue «OpenRefine versión 3.4.1 + Java para Mac».
- Haga doble clic sobre el archivo de descarga y arrastre el icono en la carpeta Aplicaciones.
- Haga doble clic en el icono y su navegador web mostrará una nueva ventana con la aplicación.
- Si al dar doble clic no abre OpenRefine en el navegador, escriba la siguiente dirección en el buscador: http://127.0.0.1:3333/
Asegúrese de que su navegador predeterminado sea Google Chrome o Mozilla Firefox.
Paso 2 - Crear un proyecto
Puede cargar datos con diferentes formatos y extensiones: TSV, CSV, SV, Excel (.xls y .xlsx), JSON, XML, RDF as XML y datos de Google Docs.
2.1. Abrir un nuevo proyecto
Abra OpenRefine y seleccione la pestaña “Create Project”. Para cargar el archivo, siga la ruta Get data from > This Computer, y haga clic en Choose Files (Fig. 1).
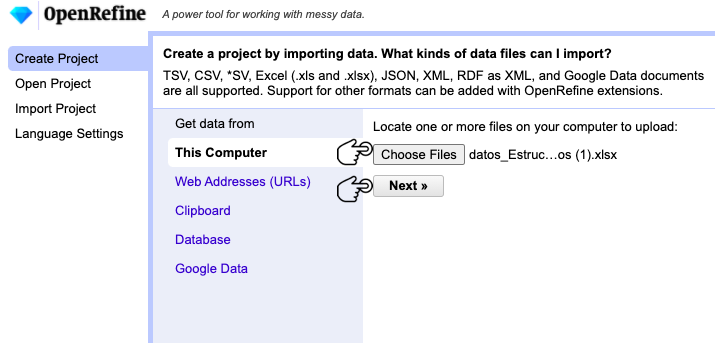
Figura 1. Creación de un proyecto en OpenRefine.
2.2. Selección del archivo
Seleccione el archivo «datos_Estructurados.xlsx» que descargó al incio del laboratorio y haga clic en Next (Fig. 1).
Puede subir varios archivos a la vez, el software unirá los archivos con base en los encabezados de las columnas.
2.3. Configuración del archivo
Tras seleccionar el archivo, aparecerá un panel de configuración. Este permite especificar el tipo de archivo que cargó y configurar la manera en la que los datos son leídos (Fig. 2).
OpenRefine hace una interpretación automática del tipo de archivo, la codificación del texto, las filas de encabezado, entre otros. El conjunto de datos de ejemplo de este laboratorio es interpretado de manera correcta y no necesita ajustes adicionales.
Si sube sus propios datos o utiliza otro formato, debe fijarse en la vista previa del archivo y ajustar la configuración de lectura detenidamente (Fig. 2).
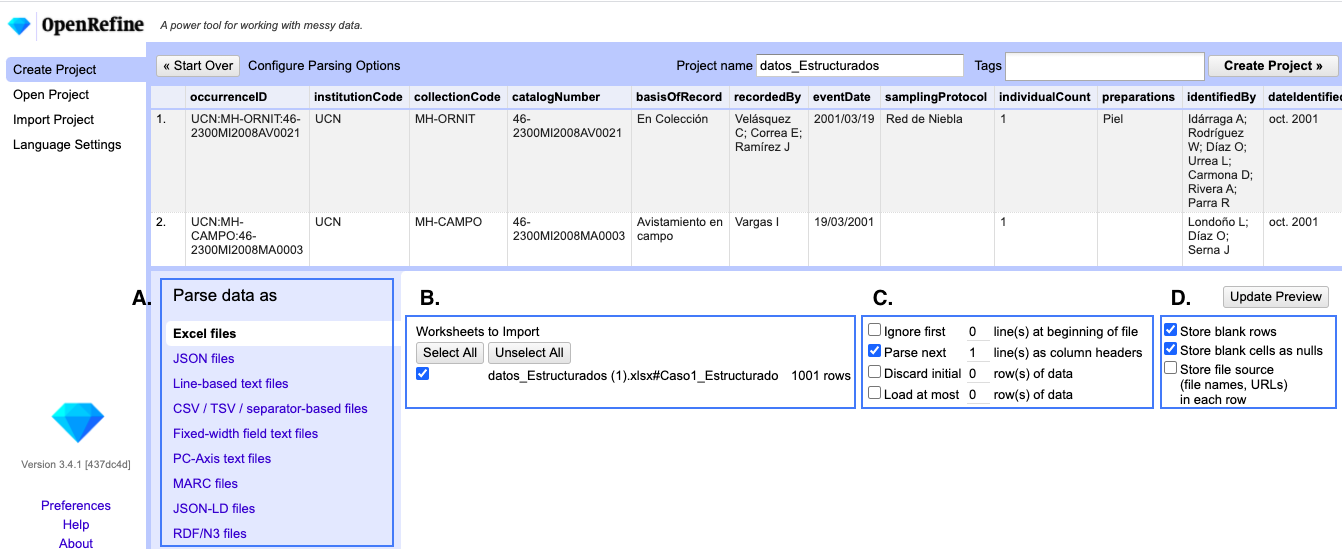
Figura 2. Opciones para configurar la lectura y carga de los datos para un archivo Excel (.xls y .xlsx): A. Tipo de archivo, B. Hojas a importar, C. Elección de filas, D. Carga de filas.
- A. Tipo de archivo: permite configurar el tipo de la fuente de datos.
- B. Hojas a importar: si carga uno o varios archivos con múltiples hojas, puede seleccionar cuáles hojas desea importar y cuáles no.
- C. Selección de filas: permite seleccionar la fila que se convertirá en el encabezado de las columnas, ignorar filas, entre otros.
- D. Carga de filas en blanco: permite especificar si se cargan filas vacías cargadas y cómo se realizará la carga.
Character encoding: al cargar datos en formato de texto plano, es posible que la previsualización muestre las tíldes (í) y las eñes (ñ) remplazadas por caracteres extraños. Si esto ocurre, seleccione la codificación UTF-8. Esto le permitirá resolver el problema, a menos que haya otro tipo de error en los datos.
2.4. Personalización del proyecto y carga del archivo
En la esquina superior derecha, verá un cuadro de texto en el que puede modificar el nombre del proyecto. En ese cuadro, escriba “Datos_OR” y haga clic en el botón Create Project (Fig. 3). Opcionalmente, puede añadir Tags (etiquetas) para organizar y filtrar los proyectos en la aplicación.
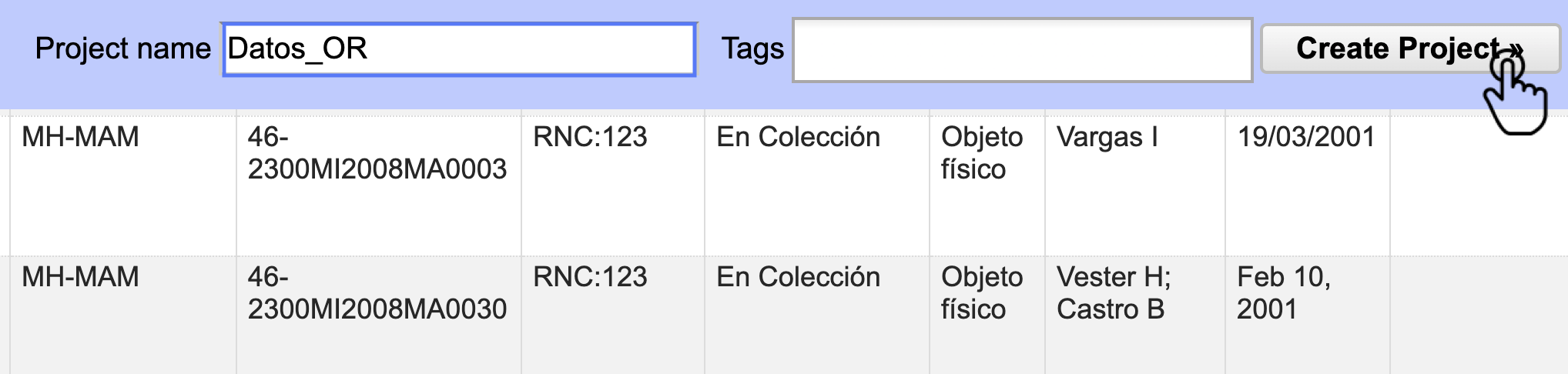
Figura 3. Configuración del proyecto, ajuste de nombre, adición de etiquetas y creación.
Espere a que cargue el archivo. Este proceso puede tomar un tiempo, dependiendo del tamaño que tenga archivo.
Paso 3 - Faceting
Es un método para filtrar los datos en conjuntos más pequeños, facilitando la validación y limpieza de los datos. Puede implementarse para texto, números y fechas.
3.1 Correcciones masivas
3.1.1. Crear un Text facet
Diríjase a la columna class, haga clic en el menú de la columna y siga la ruta Facet > Text facet (Fig. 4).
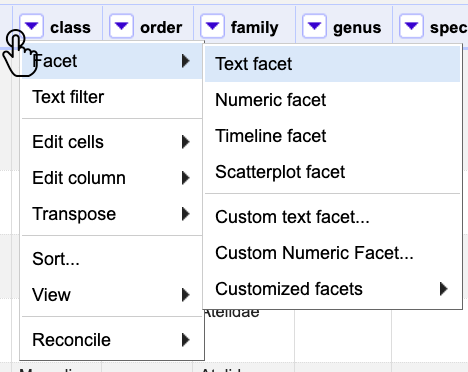
Figura 4. Creación de un Text facet.
3.1.2. Organizar el Text facet
El Text facet creado aparecerá a la izquierda de la aplicación, verá una ventana con el nombre de la columna y el Facet que acaba de crear (Fig. 5). Haga clic en count para organizar las clases de la más a la menos abundante y en name para organizarlas en orden alfabético.
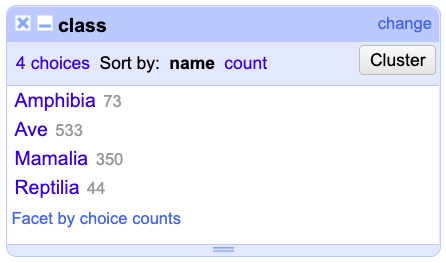
Figura 5. Vista del Text facet y las opciones para organizar las opciones de texto de la columna.
3.1.3. Corrección de los datos
Corrija las inconsistencias en los nombres de las clases Aves y Mammalia. Para esto, acerque el cursor al valor que desea corregir y haga clic en Edit. Luego, en el cuadro de texto que aparece, corrija el error y haga clic en Apply (Fig. 6). Todos los valores serán corregidos de manera automática y las celdas se transformarán de forma masiva.
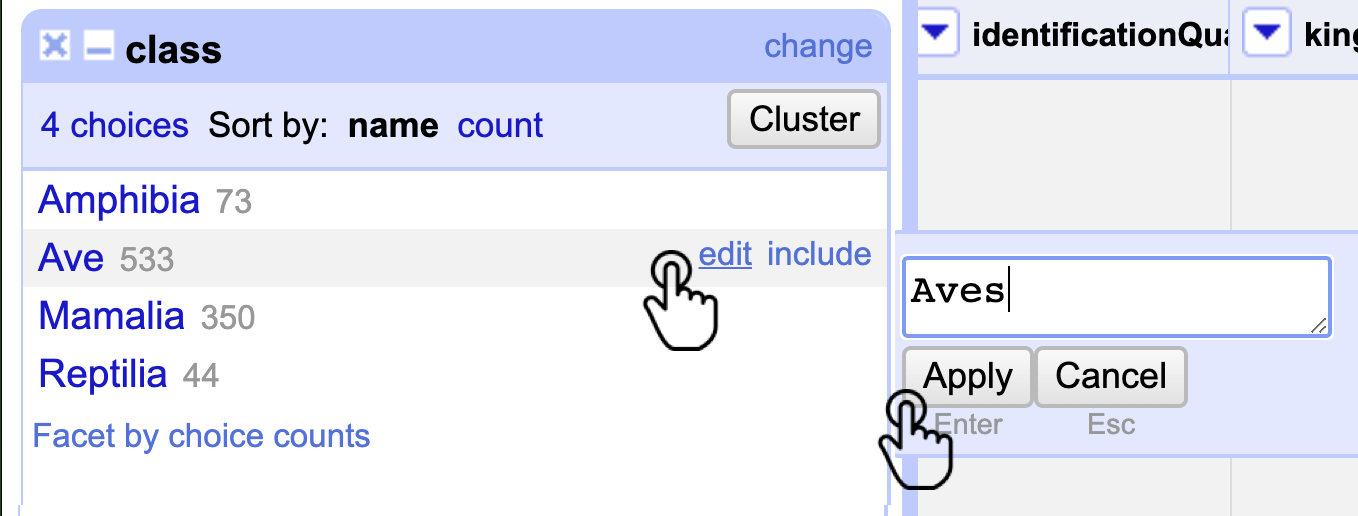
Figura 6. Corrección masiva de la columna class por medio de un Text facet.
Realice el mismo proceso con la columna basisOfRecord y sex, ajustándolas al vocabulario controlado de cada elemento (Revise el Laboratorio de estandarización) (Fig. 7).
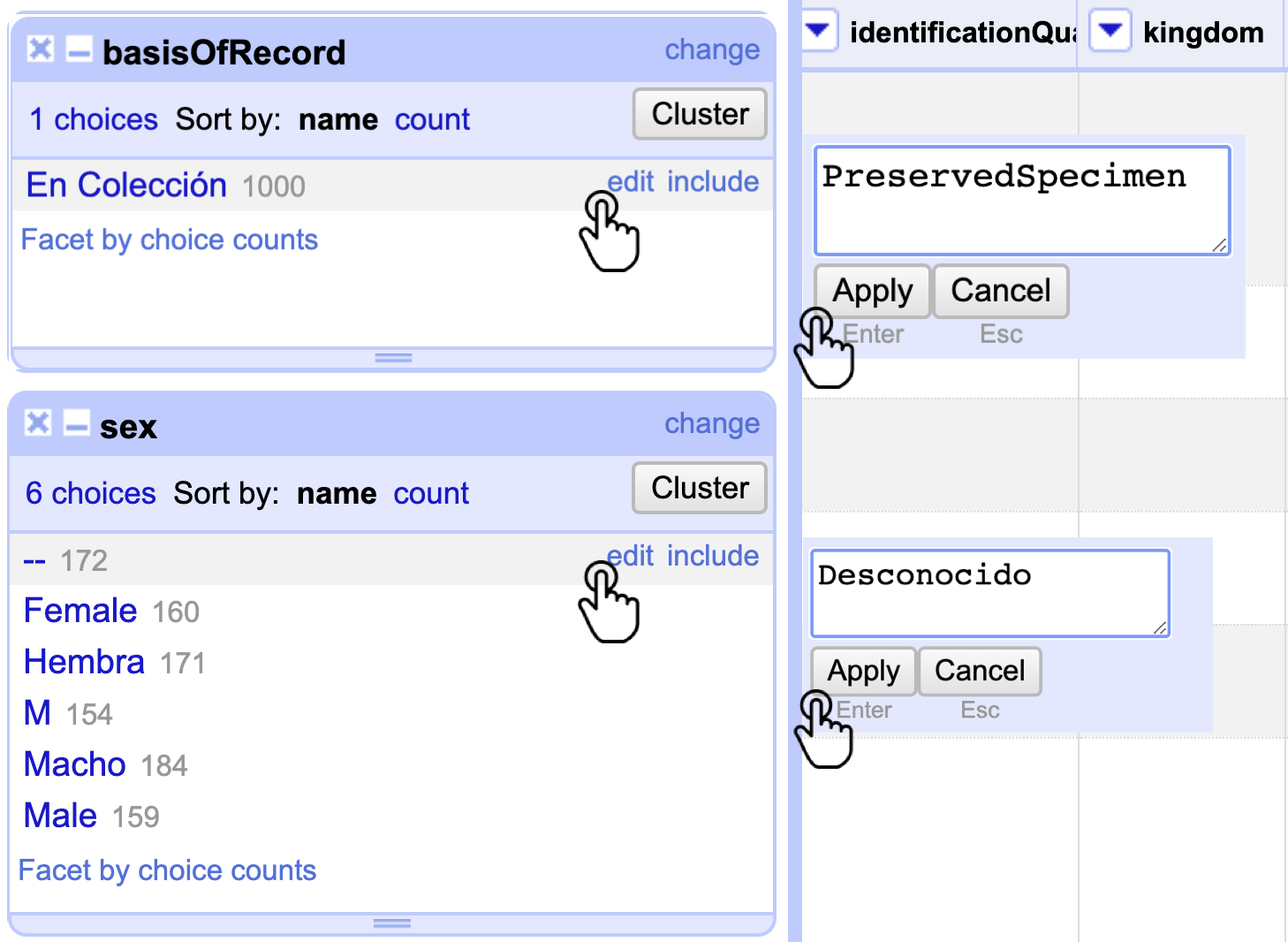
Figura 7. Corrección masiva de las columnas basisOfRecord y sex por medio de un Text facet.
Al finalizar este ejercicio, diríjase al menú lateral y seleccione la opción Remove All (Fig. 8) para quitar todos los facets y filtros que tenga en uso.
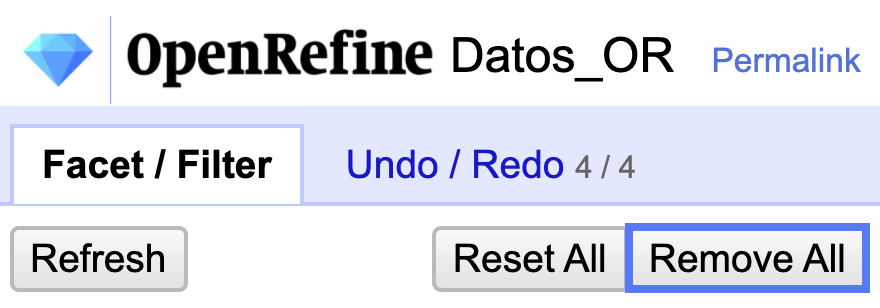
Figura 8. Remover todos los facets y filtros activos.
3.2 Limpieza de espacios en blanco
Diríjase a la columna individualCount, haga clic en el menú de la columna y realice un Text facet. A su izquierda aparecerá la ventana con el nombre de la columna y el facet que se realizó (Fig. 9).
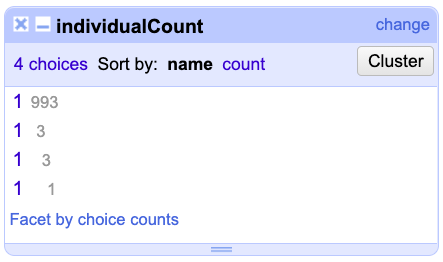
Figura 9. Vista del Text facet y las diferentes formas de documentación del elemento individualCount.
Aunque parece que los datos no tienen errores, este procedimiento evidencia que el programa ha detectado espacios extra. Por tal motivo, el facet muestra cuatro opciones diferentes para el valor 1. Corrija las inconsistencias desde el menú de la columna individualCount, siguiendo la ruta Edit Cells > Common transforms > Trim leading and trailing whitespace. Posteriormente, verá un mensaje de notificación, el cual le indicará en cuántas celdas se eliminaron espacios (Fig. 10).

Figura 10. Transformación de la columna para eliminar dobles espacios y espacios al final del texto.
Si observa la ventana del facet de individualCount, notará que ahora solo existe una opción y los espacios fueron eliminados.
Al finalizar este ejercicio, diríjase al menú lateral y seleccione la opción Remove All para quitar todos los facets y filtros que tenga en uso.
3.3 Detección de duplicados
Diríjase a la columna catalogNumber, haga clic en el menú de la columna y siga la ruta Facet > Customized facets > Duplicates facet. La ventana del facet aparecerá a la izquierda (Fig. 11).
Podemos ver que el programa ha detectado valores únicos false y valores duplicados true (Fig. 11). Haga clic en true y verá los registros. De esta manera, se pueden detectar los duplicados para un análisis posterior. En este caso, cambie el registro de “Feb 2001” por 46-2300MI2008AV0248, tanto en catalogNumber como en occurrenceID (Fig. 11).
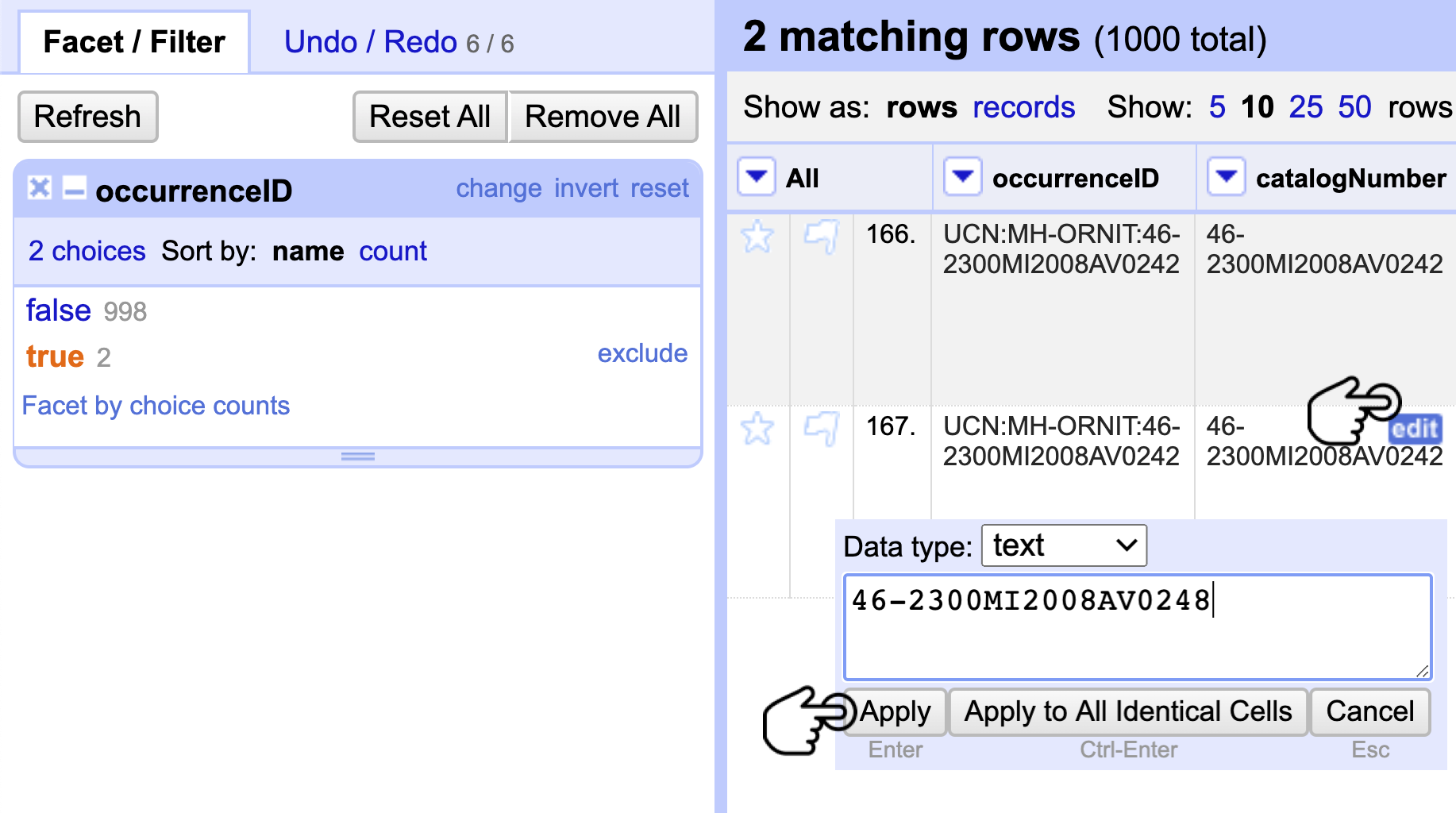
Figura 11. Revisión de los registros duplicados y corrección de los identificadores.
Al finalizar este ejercicio, diríjase al menú lateral y seleccione la opción Remove All (Fig. 8) para quitar todos los facets y filtros que tenga en uso.
Paso 4 - Filtros
4.1 Corrección combinando filtros y funciones
4.1.1. Corrección elemento **scientificName**
Diríjase a la columna scientificName, haga clic en el menú de la columna y luego en Text filter. Cuando aparezca la ventana del filtro, escriba sp. en el campo de texto y realice un Text facet en scientificName para visualizar los registros que tienen el valor mencionado (Fig. 12).
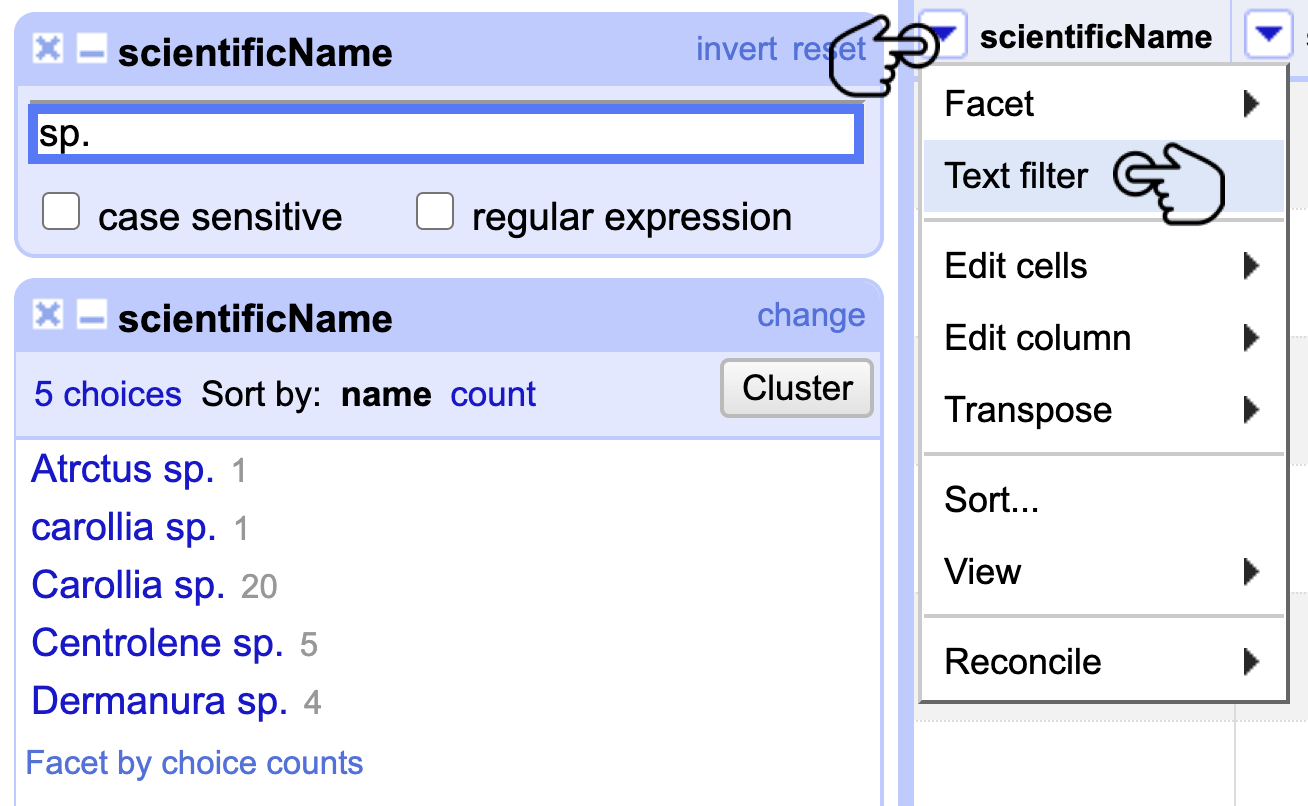
Figura 12. Aplicación de un filtro de texto a la columna scientificName e identificación de nombres científicos a corregir.
Este tipo de identificación parcial (sp.) no debe documentarse en el elemento scientificName, para ello se emplea el elemento DwC verbatimTaxonRank.
Realice un Text facet en verbatimTaxonRank y reemplace masivamente las celdas vacías (blank) con sp.. Después, haga clic en Apply (Fig. 13).
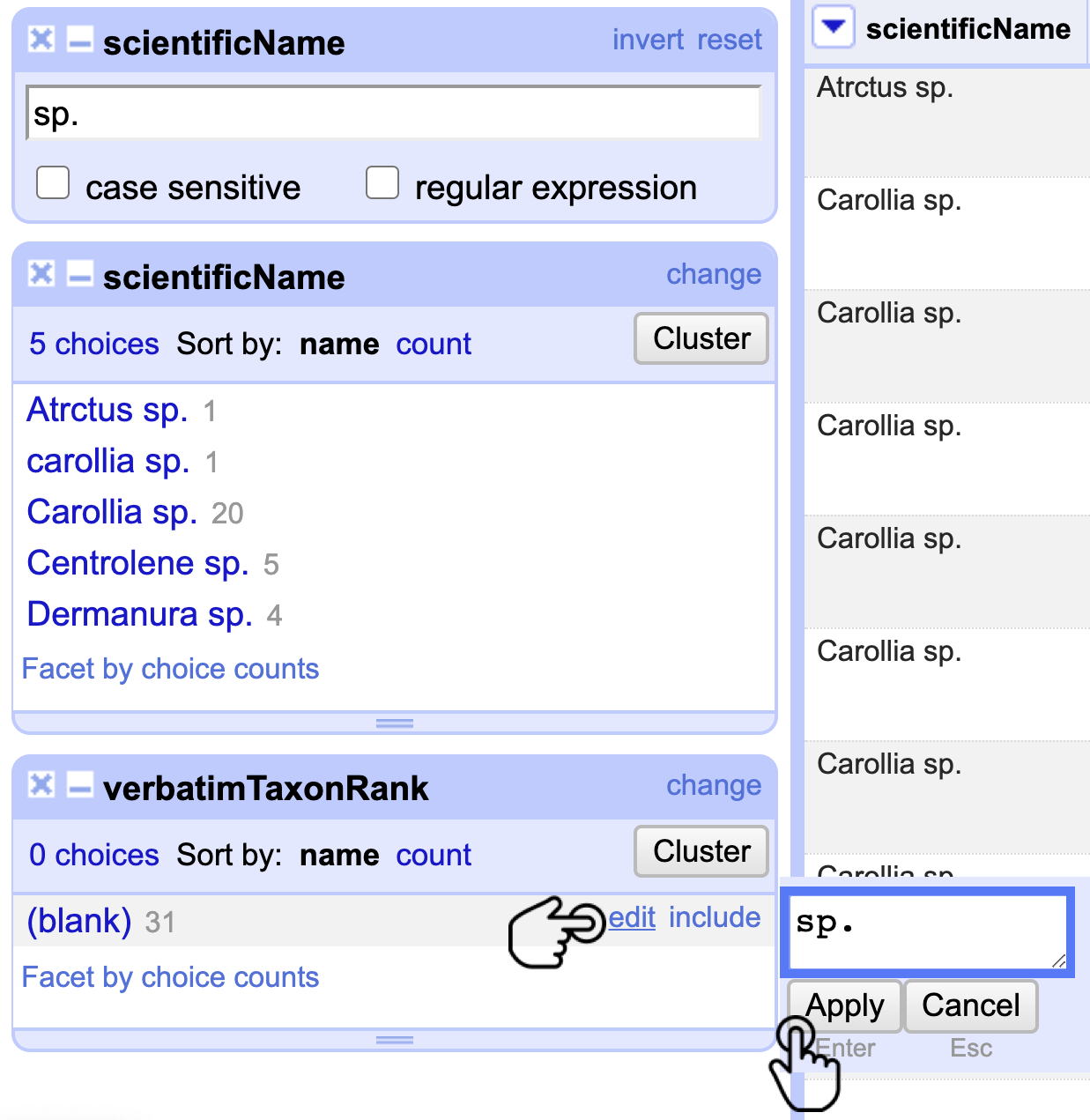
Figura 13. Documentación masiva del elemento verbatimTaxonRank.
Diríjase nuevamente al menú de la columna de scientificName y ga la ruta Edit cells > Transform. Posteriormente, ingrese el comando value.replace(" sp.","") en el cuadro de texto “Expression“. Note que la pestaña “Preview“ muestra una vista previa del resultado al aplicar el comando. Corrobore si es el cambio deseado (Fig. 14) y haga clic en OK. De inmediato, aparecerá un mensaje de confirmación de los cambios.
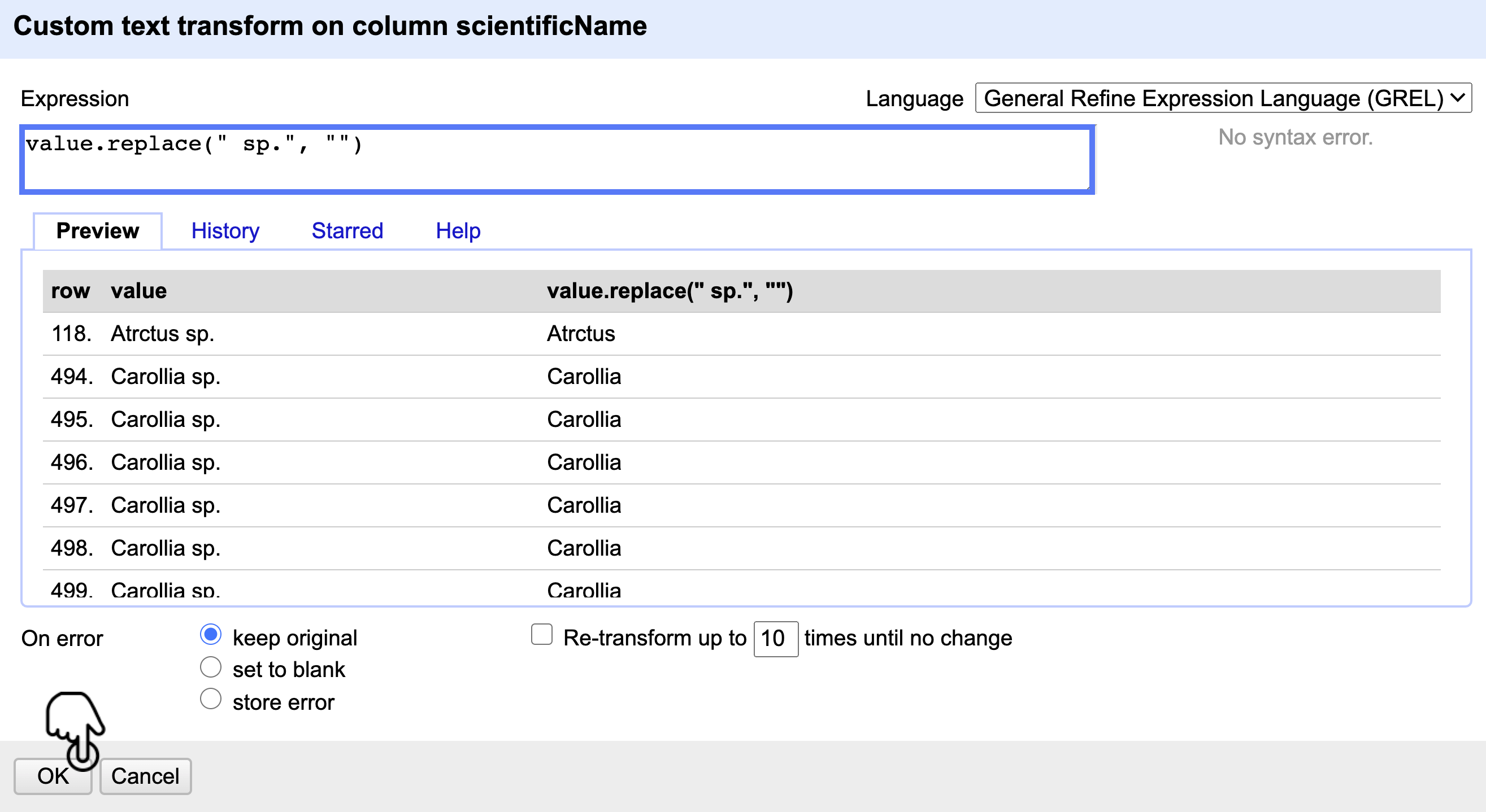
Figura 14. Transformación masiva de los datos con el comando value.replace() del lenguaje GREL de OpenRefine.
Empleando el comando value.replace se puede sustituir cualquier valor de una columna. Para ello, es necesario cambiar el contenido del paréntesis, escribiendo el valor a buscar encerrado entre comillas [ “ ] (ej. “ sp.”) y separado por una coma [ , ], seguido del valor de reemplazo entre comillas. En este caso, no hay valores de reemplazo, así que solamente se ponen las comillas [””].
Para conocer más sobre el lenguaje de programación GREL de OpenRefine, diríjase a la documentación de OpenRefine.
4.1.2. Corrección elementos **recordedBy** e **identifiedBy**
Corrija las columnas recordedBy e identifiedBy, empleando el comando value.replace del punto anterior. Para ello, reemplace en ambos elementos el carácter de separación entre los nombres "; " por el que acepta el estándar Darwin Core para este elemento " | " (Revise el Laboratorio de estandarización).
Al finalizar este ejercicio, diríjase al menú lateral y seleccione la opción Remove All (Fig. 8) para quitar todos los facets y filtros que tenga en uso.
4.2 Filtros con expresiones regulares
4.2.1. Corrección elemento **family**
Diríjase a la columna family y realice un Text facet. Haga clic en el menú de la columna y luego en Text filter para que aparezca la ventana del filtro. Marque la casilla regular expression y escriba en el cuadro de texto la expresión .*(?:(?!ae).).$. Esta expresión permite excluir todas las palabras de la columna que no terminan en ae, que corresponden a las últimas letras de la declinación en latín para la categoría taxonómica de familia (idae, ceae) (Fig, 15).
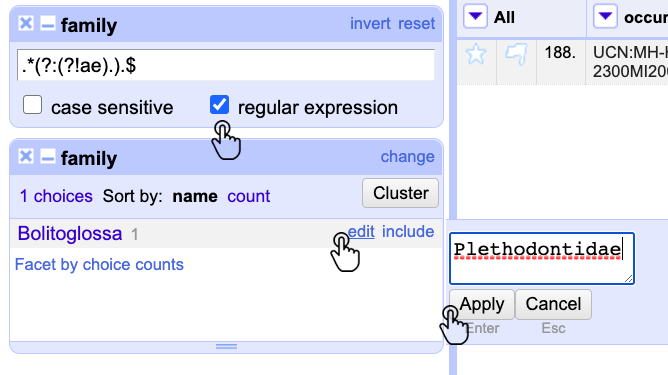
Figura 15. Uso de expresiones regulares en GREL para filtrar la columna family.
Luego de realizar el procedimiento anterior, observará que los registros que no corresponden a la categoría de familia han sido filtrados. Para editarlos, utilice las opciones aprendidas en pasos previos. En este caso particular, reemplace Bolitoglossa , que corresponde a un género, por Plethodontidae, la familia a la que pertenece el nombre científico (Fig. 15).
Para conocer más acerca de las expresiones regulares, visite la documentación de OpenRefine.
Al finalizar este ejercicio, diríjase al menú lateral y seleccione la opción Remove All (Fig. 8) para quitar todos los facets y filtros que tenga en uso.
4.2.2. Corrección elementos **scientificName** e **identificationQualifier**
Diríjase a la columna scientificName, haga clic en el menú de la columna y luego en Text filter. Cuando aparezca la ventana del filtro, marque la casilla regular expression y escriba en el campo de texto la expresión [.]. Luego, realice un Text facet para visualizar los registros con este elemento (Fig. 16).
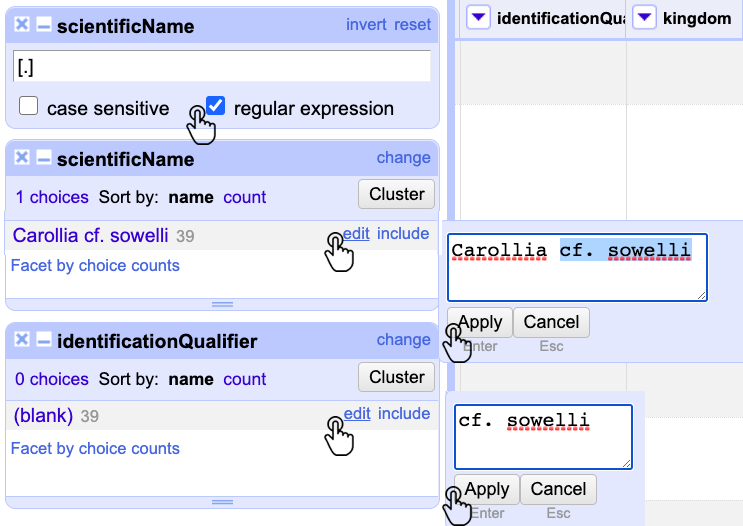
Figura 16. Uso de expresiones regulares en GREL para filtrar y corregir las columnas scientificName identificationQualifier.
Al terminar el procedimiento anterior, observará los registros que cumplen con el criterio de la expresión regular. El elemento identificationQualifier está diseñado para almacenar este tipo de información, mientras que el elemento scientificName debe encontrarse sin calificadores.
Para ajustar ambos elementos, aplique un Text facet en identificationQualifier y reemplace el blank por cf. sowelli; además, borre este mismo texto en el scientificName (Fig. 16). De esta manera, se corrigen masivamente todos los campos.
El grado de incertidumbre de la identificación puede indicarse agregando varios calificativos, como “aff.” y “cf.”, al nombre científico. El calificativo se escribe después del elemento al que corresponde la incertidumbre de identificación (género o especie).
- aff.: similar o limítrofe, indica que otra especie tiene afinidad con la especie mencionada, pero no es idéntica a ella.
- cf.: comparar con, describe un espécimen que es difícil de identificar e indica diversos grados o tipos de incertidumbre sobre el taxon, los cuales pueden usarse de manera diferente según el autor.
Finalmente, debe documentarse el género Carollia en scientificName y asociarlo con el calificativo cf. sowelli en identificationQualifier (Fig. 17).
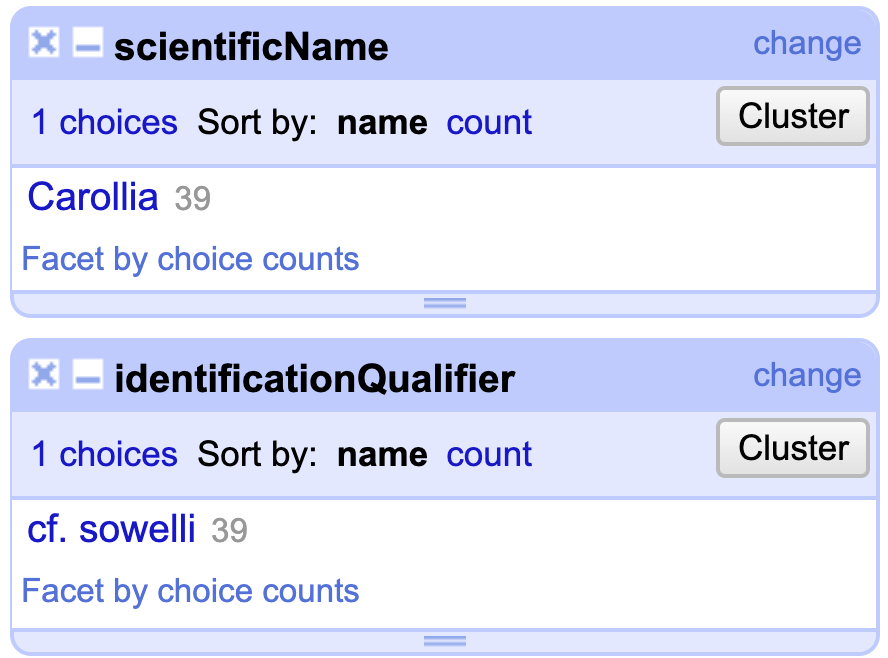
Figura 17. Documentación corregida y correcta de los elementos scientificName e identificationQualifier.
Al finalizar este ejercicio, diríjase al menú lateral y seleccione la opción Remove All (Fig. 8) para quitar todos los facets y filtros que tenga en uso.
Paso 5 - Conjuntos
Diríjase a la columna recordedBy y despliegue el menú. Posteriormente, haga clic en Text facet para que la ventana del facet con más de 200 opciones (choices) diferentes (Fig. 18).
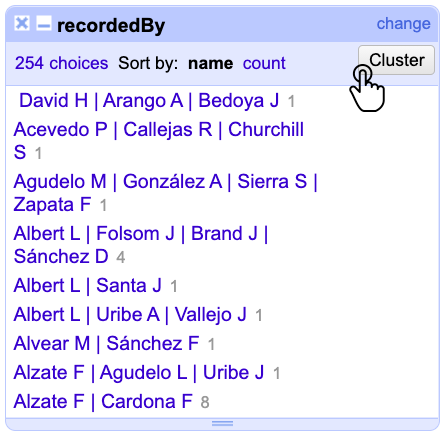
Figura 18. Facet y opciones del elemento recordedBy.
En la parte superior derecha, verá el botón Cluster. Al hacer clic en él (Fig. 18), aparecerá la ventana de “Cluster & Edit“ para la columna recordedBy (Fig. 19).
Podrá ver la siguiente información:
- Cluster size: La cantidad de versiones del dato que el algoritmo identifica como similares.
- Row count: El número de registros por cluster.
- Values in cluster: Los valores seleccionados por el algoritmo para esa agrupación y el número de registros por valor.
- Merge?: En este cuadro se selecciona si los valores se fusionan en el valor que propone el algoritmo por defecto o el documentado por el usuario.
- New cell value: En este campo de texto se puede escribir un valor completamente nuevo para el cluster. También se puede hacer clic en cualquier valor para asignarlo como valor por defecto.
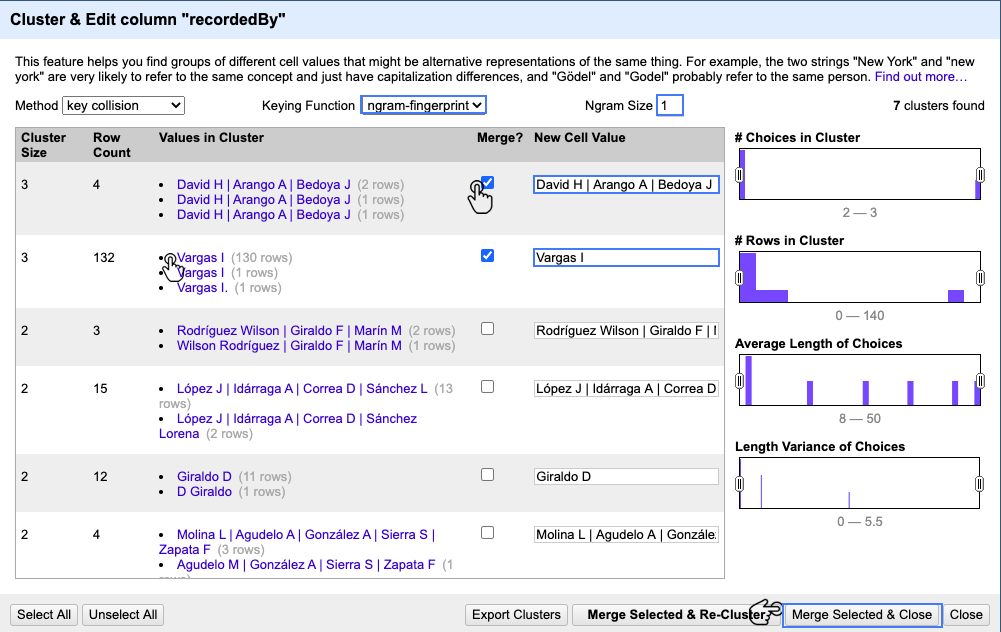
Figura 19. Detalle de la ventana ventana de Cluster & Edit para hacer realizar clusters y las opciones de configuración disponibles.
Vaya a Keying Function, seleccione ngram-fingerprint y en Ngram Size escriba 1 (Fig. 19).
Para conocer más acerca de los algoritmos diríjase a la documentación de OpenRefine.
-
Para el primer cluster asigne un valor nuevo, para esto vaya al cuadro de texto de
New cell valuey escribaDavid H | Arango A | Bedoya J(dejando espacios sencillos). Luego haga check en el cuadro deMerge?para ese cluster (Fig. 19). -
Para el segundo cluster haga clic en
Vargas I(la primera opción: sin espacios adicionales), automáticamente el valor enNew cell valuecambiará y la casillaMerge?se chequeará (Fig. 19). -
Con los restantes evalúe si se deben o no agrupar dependiendo de las opciones disponibles y escoja en tal caso si selecciona o no la casilla.
Una vez escoja las entradas que desee fusionar vaya a Merge Selected & close para agrupar los valores y volver a la ventana principal.
Observe que la cantidad de opciones de datos disminuyó y que la primera entrada de nombres ha cambiado, es decir la información se simplificó y organizó correctamente gracias a este proceso.
Al finalizar este ejercicio diríjase al menú lateral y seleccione la opción Remove All (Fig. 8). Así removerá todos los Facets y Filtros que tenga en uso.
Paso 6 - Servicios externos vía API's
En este ejercicio se utiliza el API(Ver definición en el glosario) de GBIF para verificar la validez taxonómica de una lista de nombres determinada.
Árbol taxonómico GBIF
GBIF fácilita un árbol taxonómico robusto a partir de la agrupación de reconciliación de diversos grupos biológicos y proveedores de contenido (Tabla 1), cada uno de las cuales es soportado por una comunidad de científicos. Este árbol permite la integración de múltiples fuentes de datos fácilitando las busquedad y descargas del portal, y esta en constante actualización.
Tabla 1. Principales fuentes a partir de las cuales se consolida el árbol taxonómico de GBIF.
| Proveedor * | Enlace |
|---|---|
| CoL | http://www.catalogueoflife.org/ |
| International Barcode of Life project (iBOL) | https://ibol.org/ |
| World Register of Marine Species (WoRMS) | http://www.marinespecies.org/ |
| Index Fungorum | http://www.indexfungorum.org/ |
| Integrated Taxonomic Information System (ITIS) | http://www.itis.gov/ |
| International Plant Names Index | http://www.ipni.org/ |
| The Paleobiology Database | http://www.paleodb.org/ |
*Para una lista completa de los proveedores y descripción de los mismos ingrese al GBIF Backbone Taxonomy.
Preparación de los datos
Elimine los facets o filtros que tenga activos. Para tener una aproximación inicial al funcionamiento del API diríjase a la columna recordedBy y realice un Text Facet. Haga clic en la opción count y seleccione al investigador(es) con mayor número de registros asociados (Vargas I) (Fig. 20).
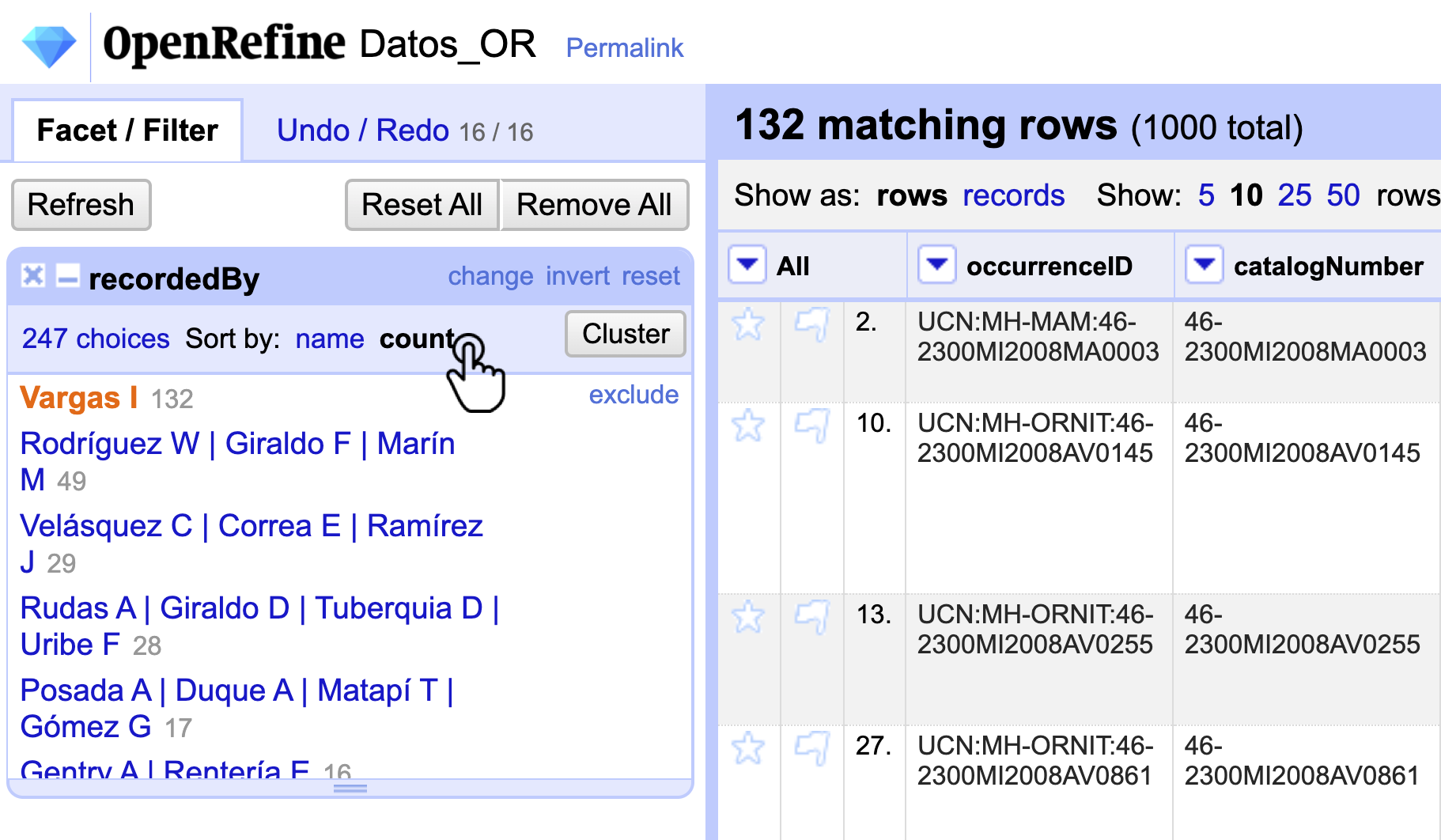
Figura 20. Filtro por conteo en recordedBy y selección de la opción con más registros.
Vaya a la columna scientificName. Es importante que estos nombres no contengan calificadores como aff., cf., sp. o spp., de ser este el caso, elimínelos como se mostró en los pasos anteriores y deje solamente como valor el nombre científico sin autoría.
Cree la columna NomAPI
Para realizar la validación a través del API es necesario que los espacios en blanco en cada nombre científico sean reemplazados por un valor que reconozca el API (“%20”).
Para ello vaya a Edit column > Add column based on this column e introduzca la expresión (tal y como aparece) value.replace(" ","%20") y nombre la columna NomAPI (Fig. 21).
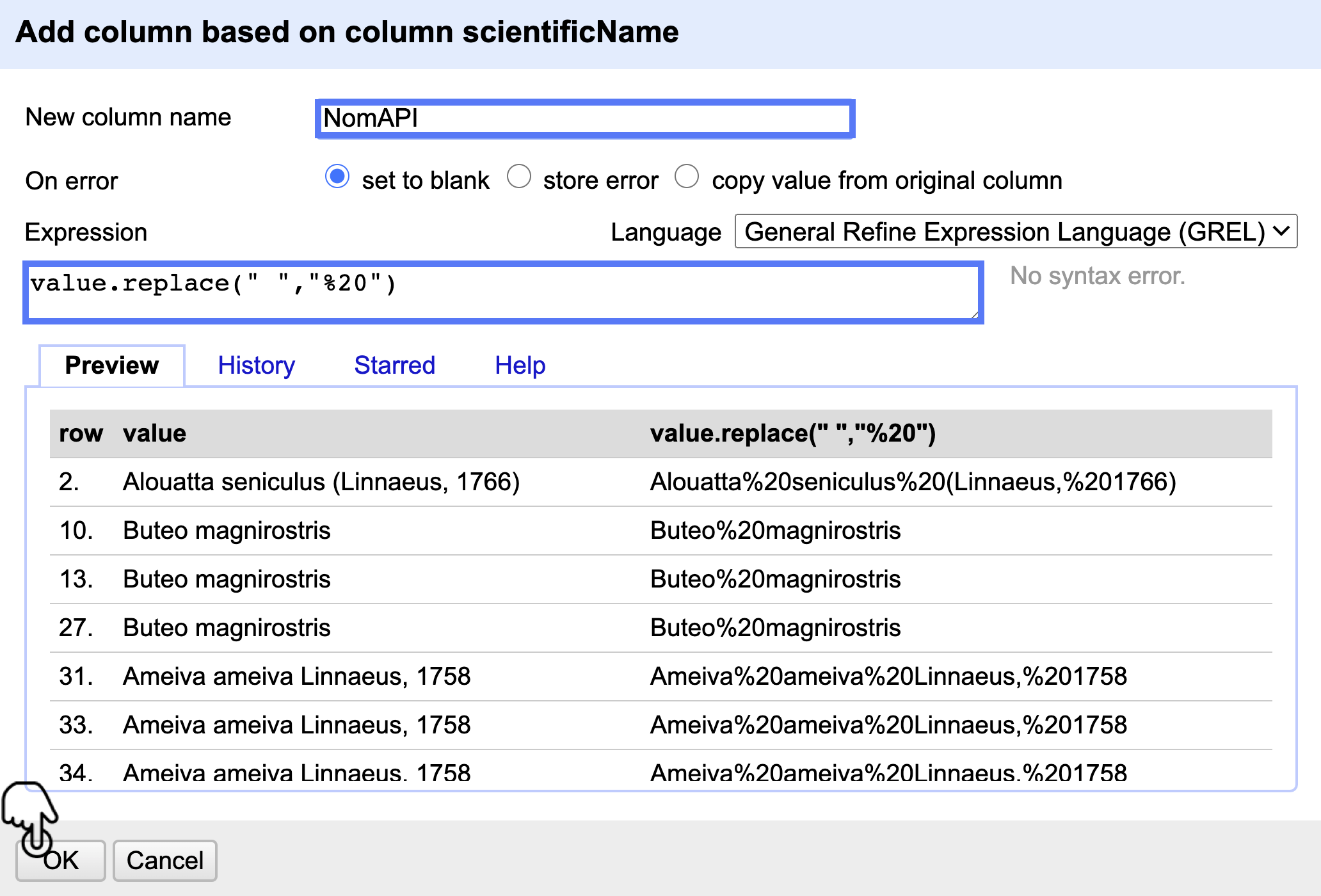
Figura 21. Creación de la nueva columna NomAPI.
LLamado al API a partir del nombre científico
Cree una nueva columna llamada validTax a partir de la columna NomAPI, para esto siga la ruta Edit column > Add column by fetching URLs… e introduzca la expresión "http://api.gbif.org/v1/species/match?strict=true&name="+value. En el campo Throttle delay escriba 5, haga clic en OK y espere a que finalice el proceso (Fig. 22).
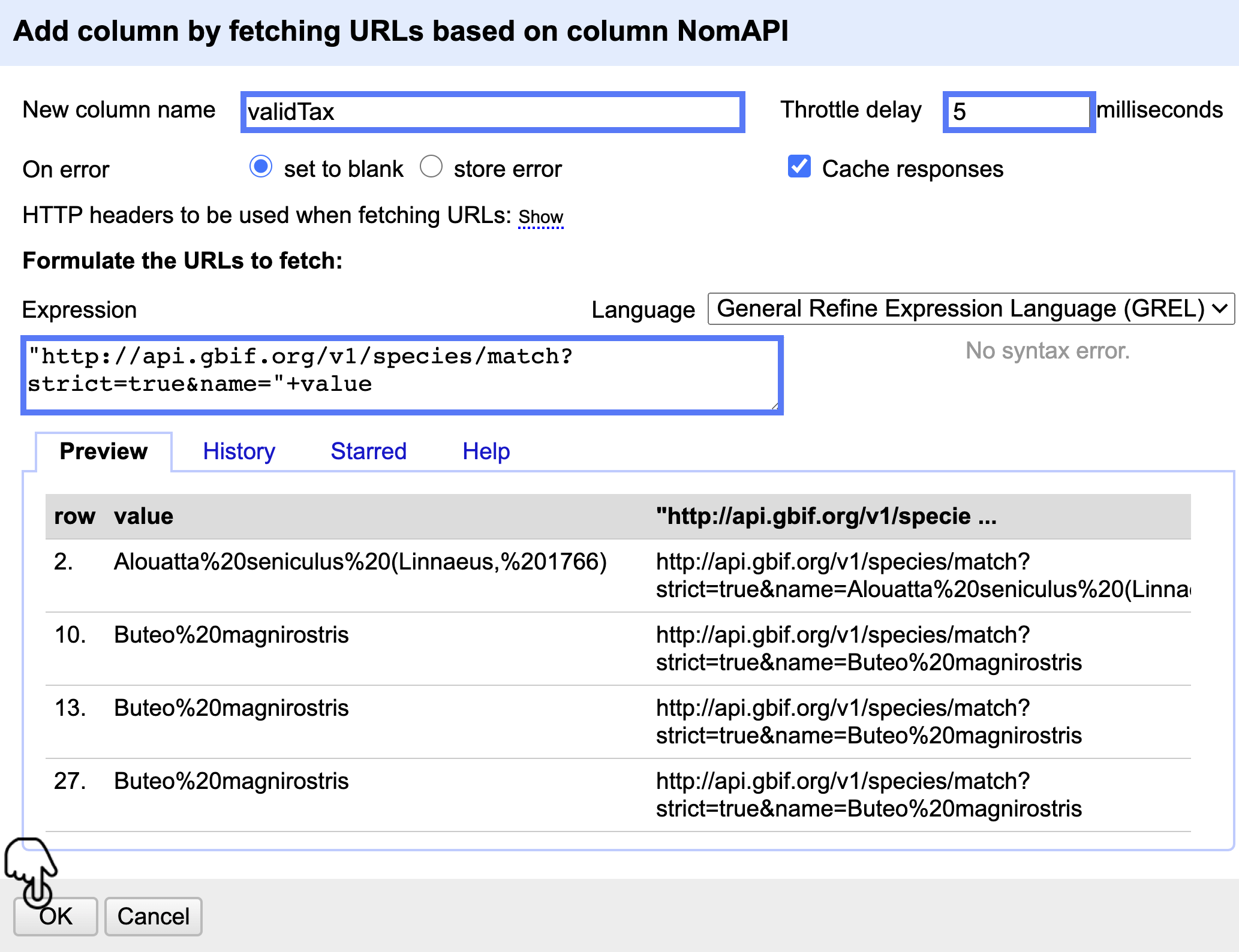
Figura 22. Creación de la nueva columna validTax.
El tiempo de consulta depende de la cantidad de información, la velocidad de la red, y la memoria RAM del computador - para este caso solo tardará un par de minutos.
Podrá observar que en cada celda de la columna validTax aparecen expresiones a partir del llamado al API de GBIF para cada nombre científico consultado (Fig. 23).

Figura 23. Visualización de la columna validTax.
Extracción de la información obtenida
Para observar claramente los resultados y obtener la validación del nombre científico agregue una columna basada en validTax haciendo clic en Edit column > Add column based on this column llamada Match, e introduzca la expresión value.parseJson().get("matchType")(Fig. 24).
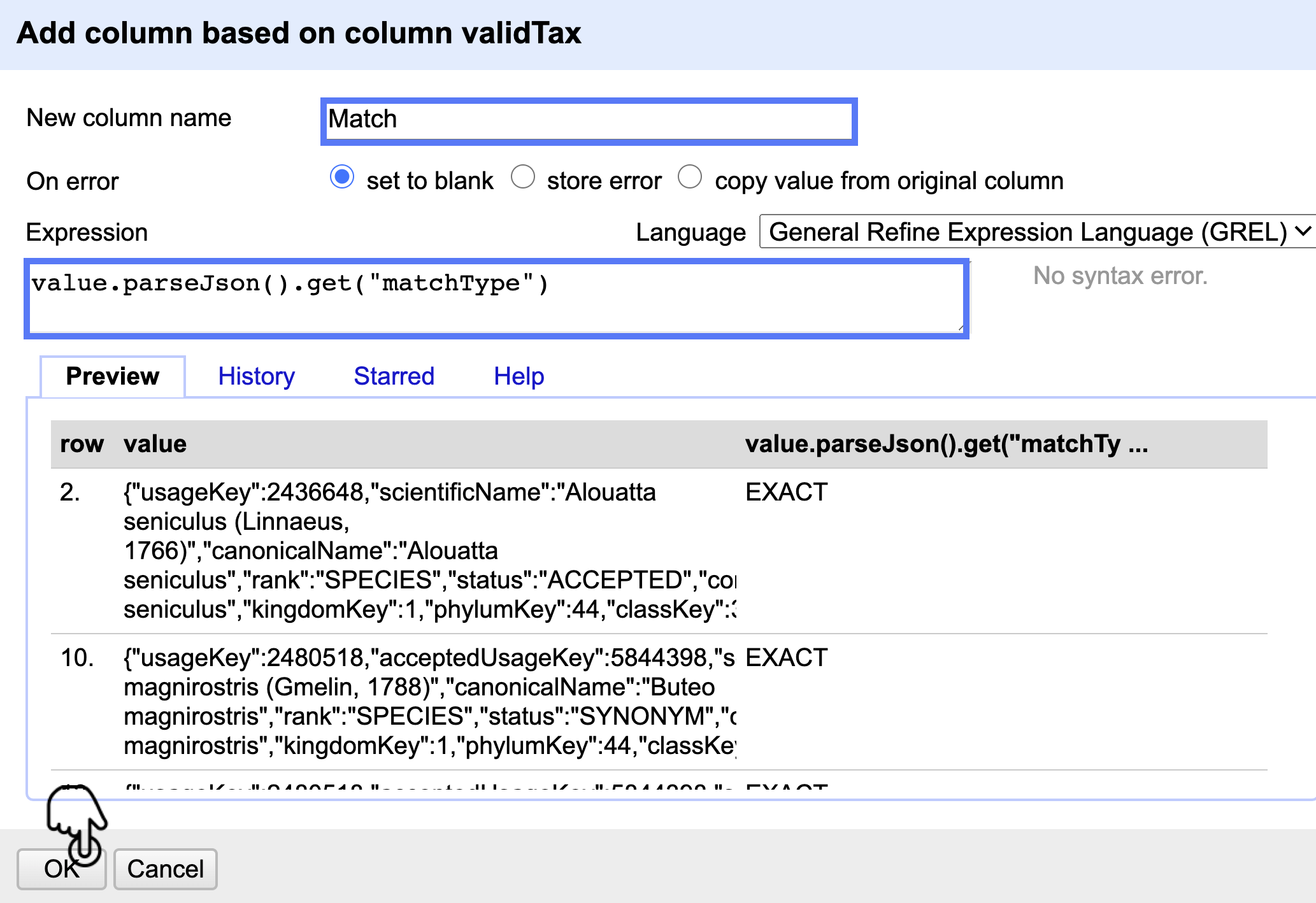
Figura 24. Creación de la columna Match a partir de la información obtenida del API.
Validación del nombre científico
Realice un Text facet en la columna Match y seleccione Fuzzy, esta opción denota los nombres científicos con los que no hubo coincidencia exacta entre el conjunto de datos y el árbol taxonómico de GBIF. No se encuentra coincidencia total para este caso con Dermanura cinereus ni Dermanura glaucus (Fig. 25).
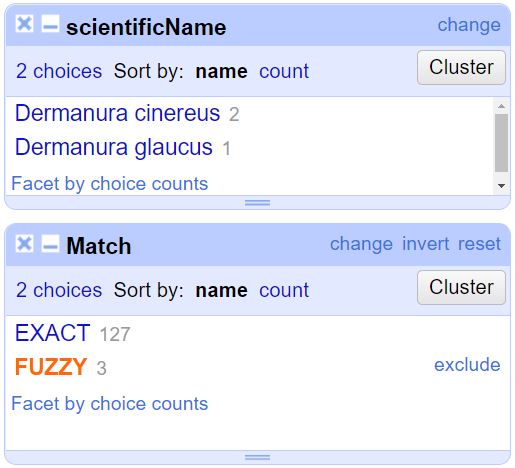
Figura 25. Resultado del Facet para Fuzzy.
GBIF también le retorna a través del API una posible opción de nombres científicos válidos de acuerdo a los que no reconoció totalmente, evalué estos nombres e indentifique si debe hacer una corrección.
Agregue una nueva columna llamada validName a partir de la columna validTax, para esto siga la ruta Edit column > Add column based on this column e introduzca la expresión value.parseJson().get("species") y haga clic en OK (Fig. 26).
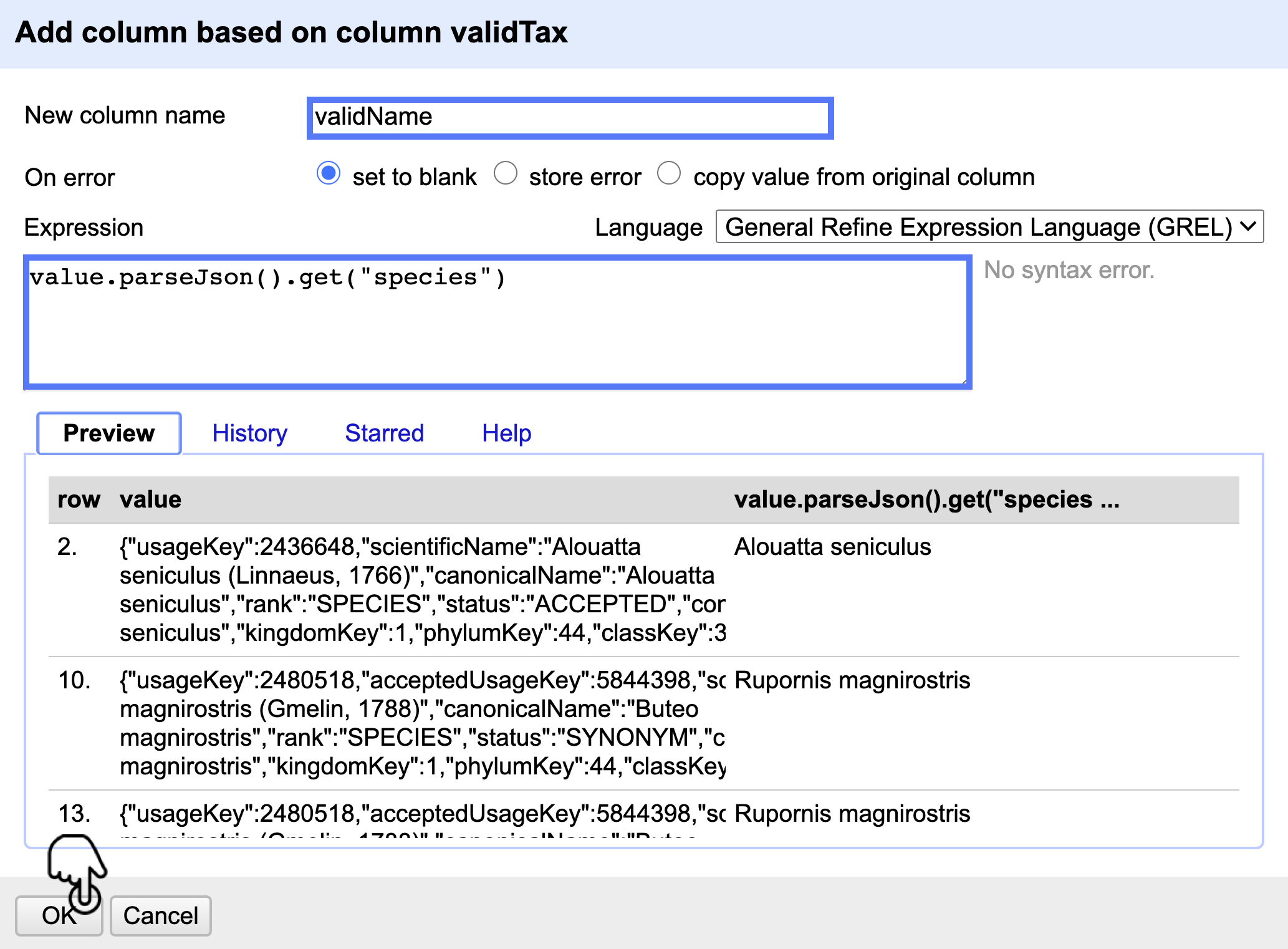
Figura 26. Creación de la nueva columna validName.
Haciendo un Text Facet en la columna validName verá que GBIF reconoce que la especie que seguramente desea documentar es Artibeus cinereus y Artibereus glaucus, respectivamente (Fig. 27A). Corrija y edite entonces las inconsistencias en la columna scientificName de acuerdo al validName (Fig. 27B).
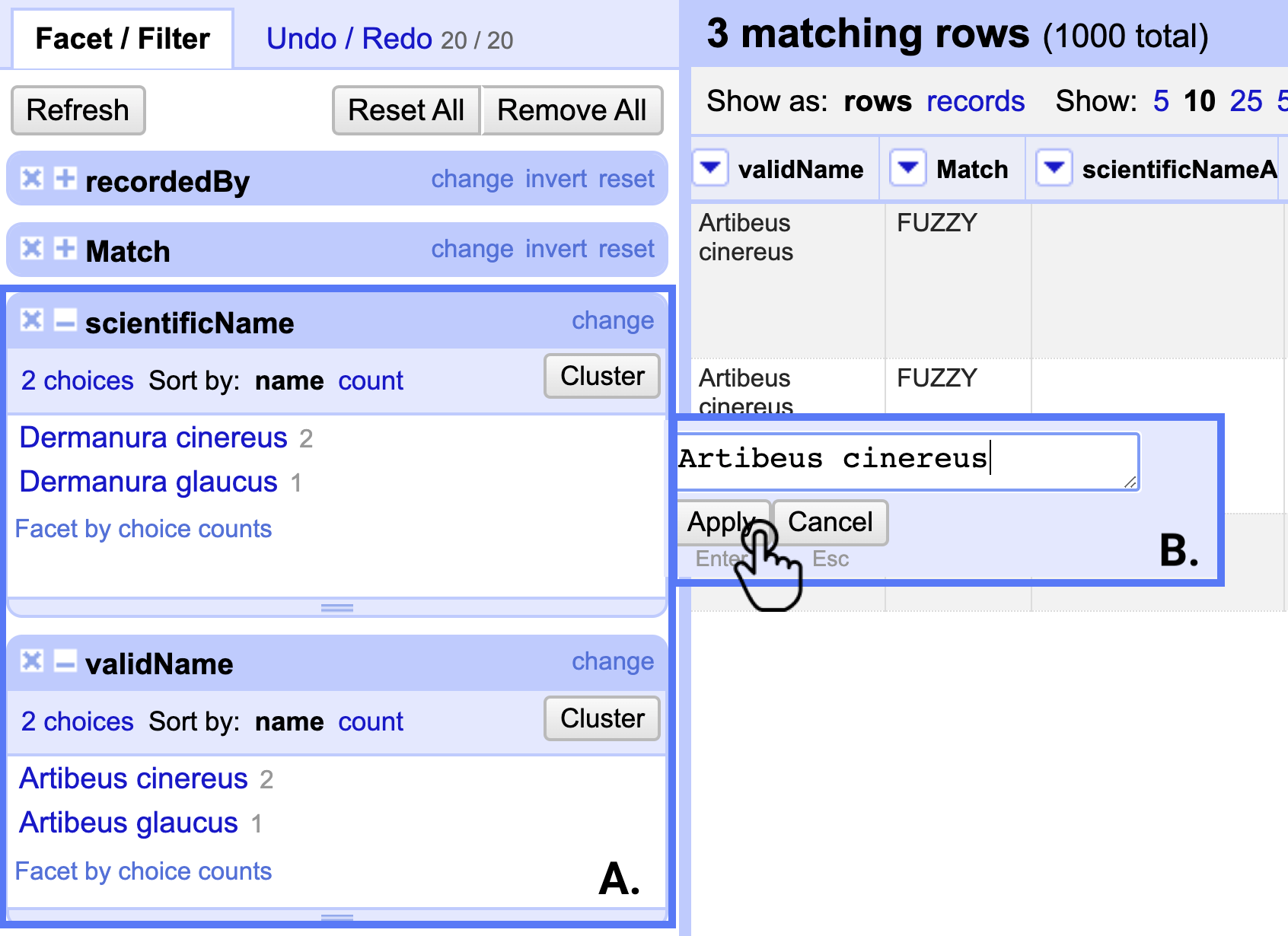
Figura 27. Corrección del nombre científico en OpenRefine. A. Filtro para el nombre científico y la sugerencia de GBIF. B. Corrección en el nombre científico.
Habiendo realizado el proceso de verificación y limpieza de nombres científicos elimine las columnas adicionales que se crearon para este fín (NomAPI, validTax, Match y validName). Para ello siga la ruta Edit column > Remove this column (Fig. 28).
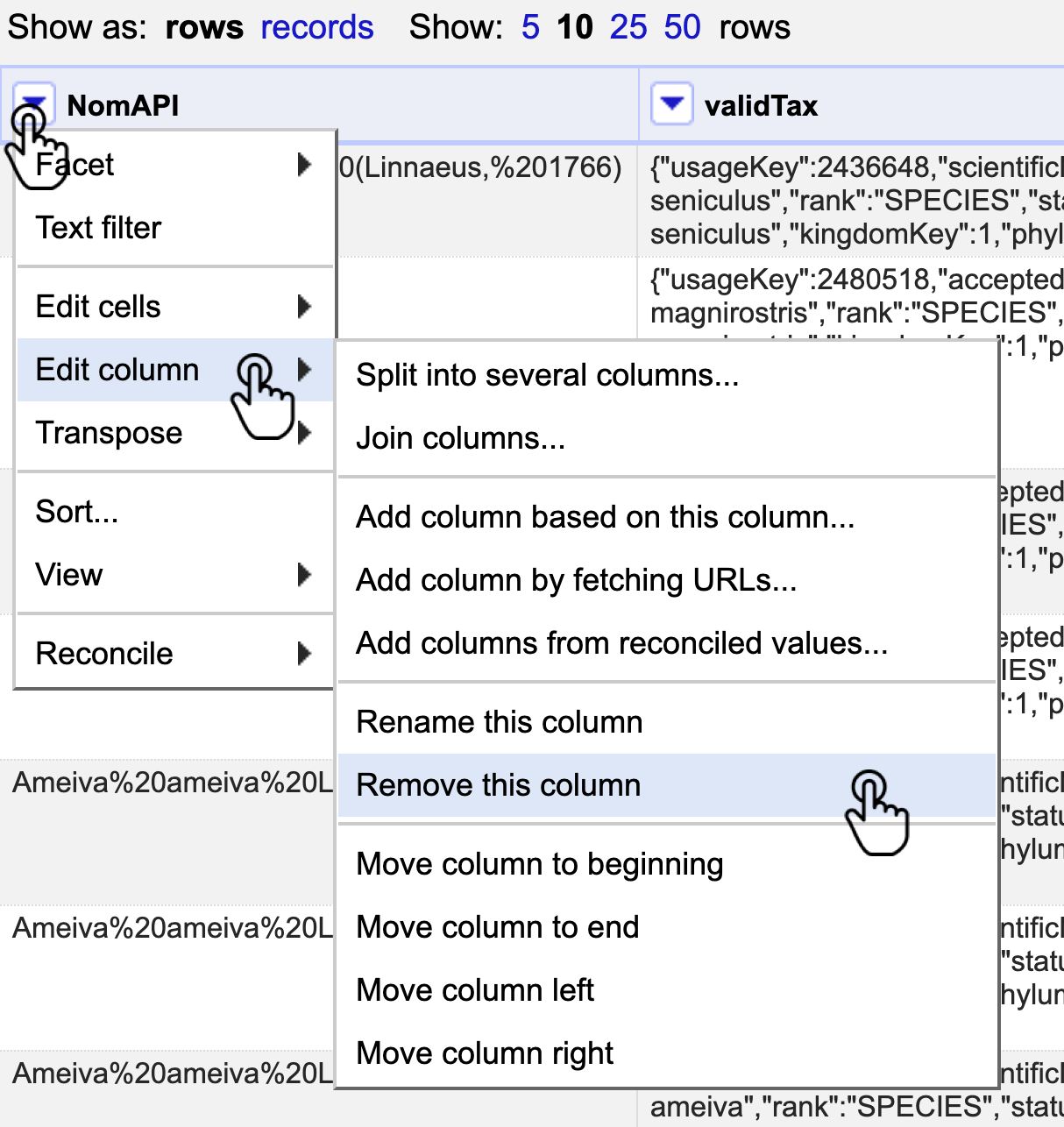
Figura 28. Ruta para eliminar una columna.
Paso 7 - Modificación masiva de celdas
Para hacer una modificación en todas las celdas del archivo, diríjase a la primera columna presente All ,seleccione el menu desplegable y la opción Transform (Fig. 29).
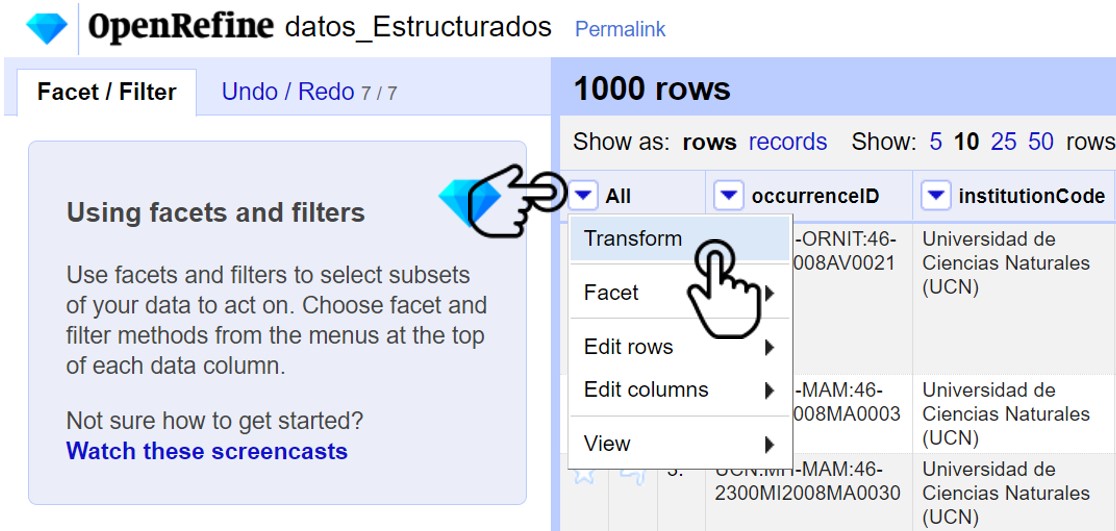
Figura 29. Selección del menu para hacer el cambio masivo.
En la pestaña emergente introduzca la fórmula value.trim().replace(/\u00A0/,' ').replace(/\s+/,' '), esta elimina dobles espacios, saltos de línea y algunos carácteres no reconocibles. Al hacer clic en OK le mostrará otra pestaña donde puede elegir las columnas a las que desea aplicarles la modificación. Deje la opción por defecto con todas las columnas y de clic en OK (Fig. 30).
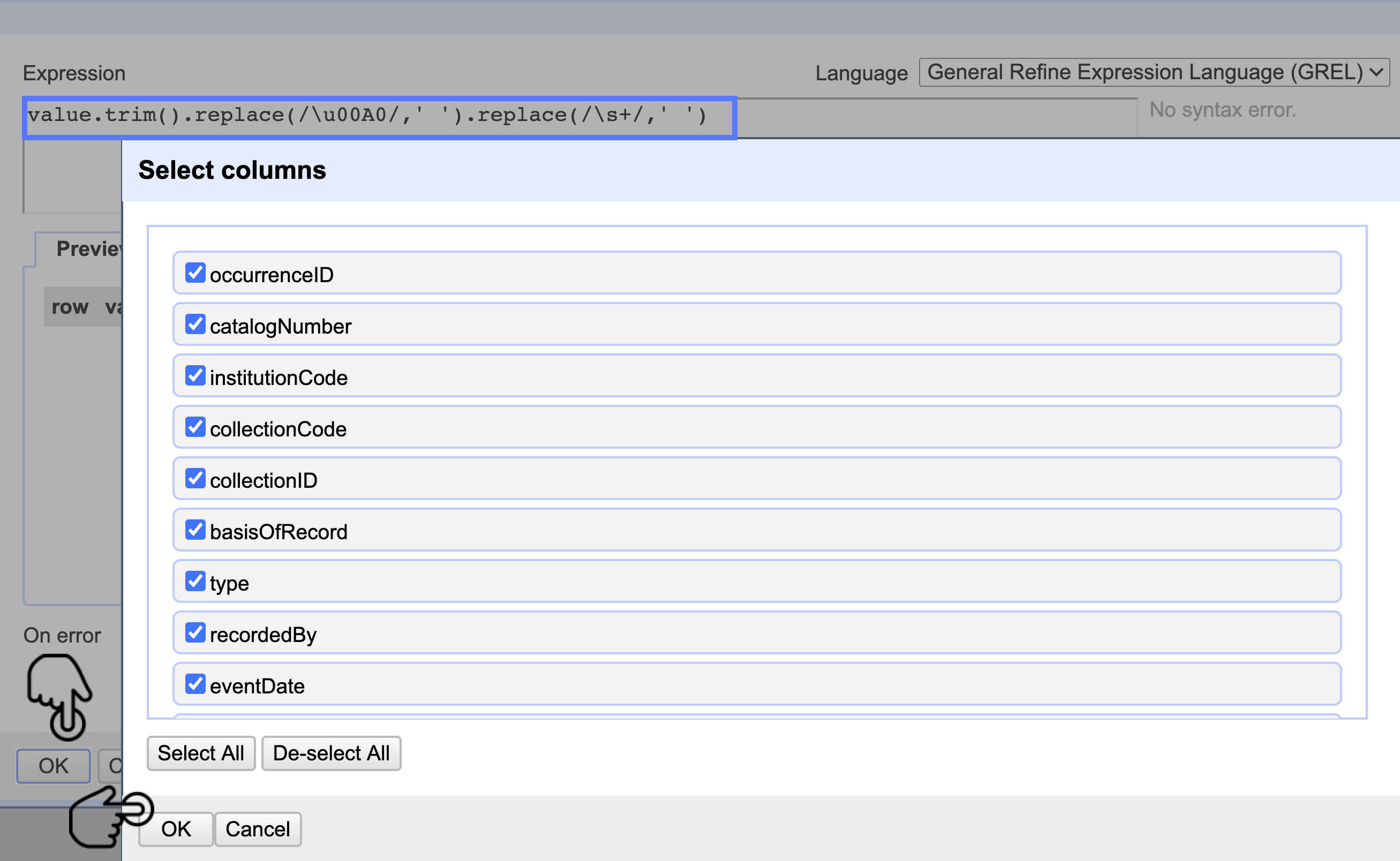
Figura 30. Pestaña para introducir la función de transformación, y para seleccionar las columnas a las cuales se aplica la función.
El proceso puede tardar algunos segundos dependiendo del número de columnas y celdas.
Paso 8 - Exportación
8.1 Exportar un archivo
Existen múltiples maneras de exportar los archivos en OpenRefine, la siguiente es la más confiable y con la mayor cantidad de opciones. Dirijase a la esquina superior derecha y siga la ruta Export > Custom tabular exporter… y le mostrara la ventada de exportación (Fig. 31).
En la pestaña Content de la ventana emergente tiene encontrará varias opciones para personalizar la exportación, entre estas:
- Select and Order Columns to Export: le permite seleccionar las columnas y el orden en que se van a exportar.
- Ignore facets and filters and export all rows: si al momento de exportar el archivo tiene Facets y Filtros activos, esta opción le permitirá ignorarlos, descargando así todo el conjunto de datos.
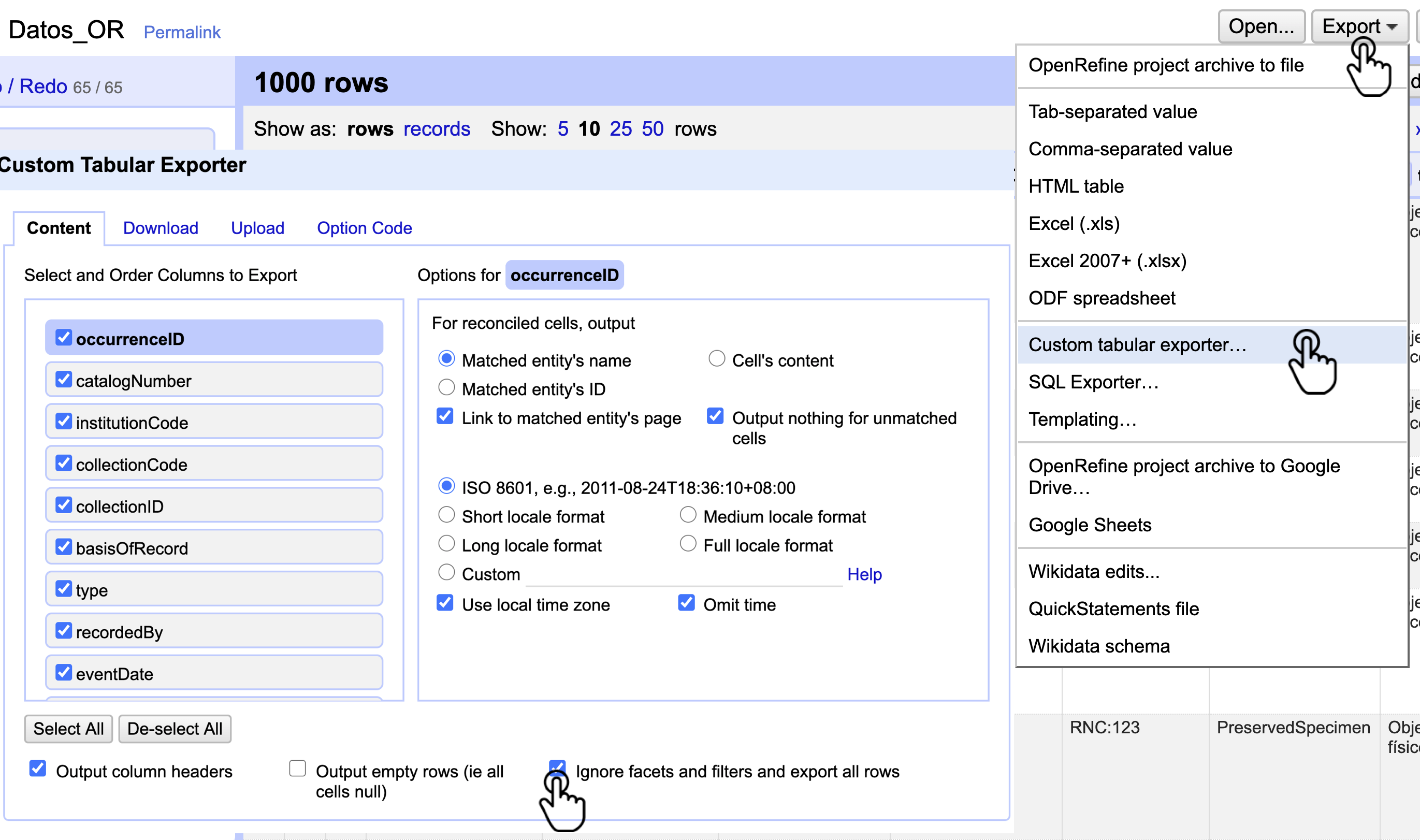
Figura 31. Ruta para expotar el archivo y ventana content.
Vaya a la pestaña Download, donde podrá configurar el formano en el cuál se descargan los datos:
- Line-based text formats/Other formats: si va a descargar los datos en formato de texto plano le permite selecionar el separado de las olumnas.
- Line separator:si va a descargar los datos en formato de texto plano le permite seleccionar el separador de las filas.
- Character encoding: le permite seleccionar la codificación de los datos. Se recomienda siempre utilizar UTF-8.
Para este caso, use Other formats y elija la opción Excel in XML(.xlsx), haga clic en Download y guarde su archivo (Fig. 32).
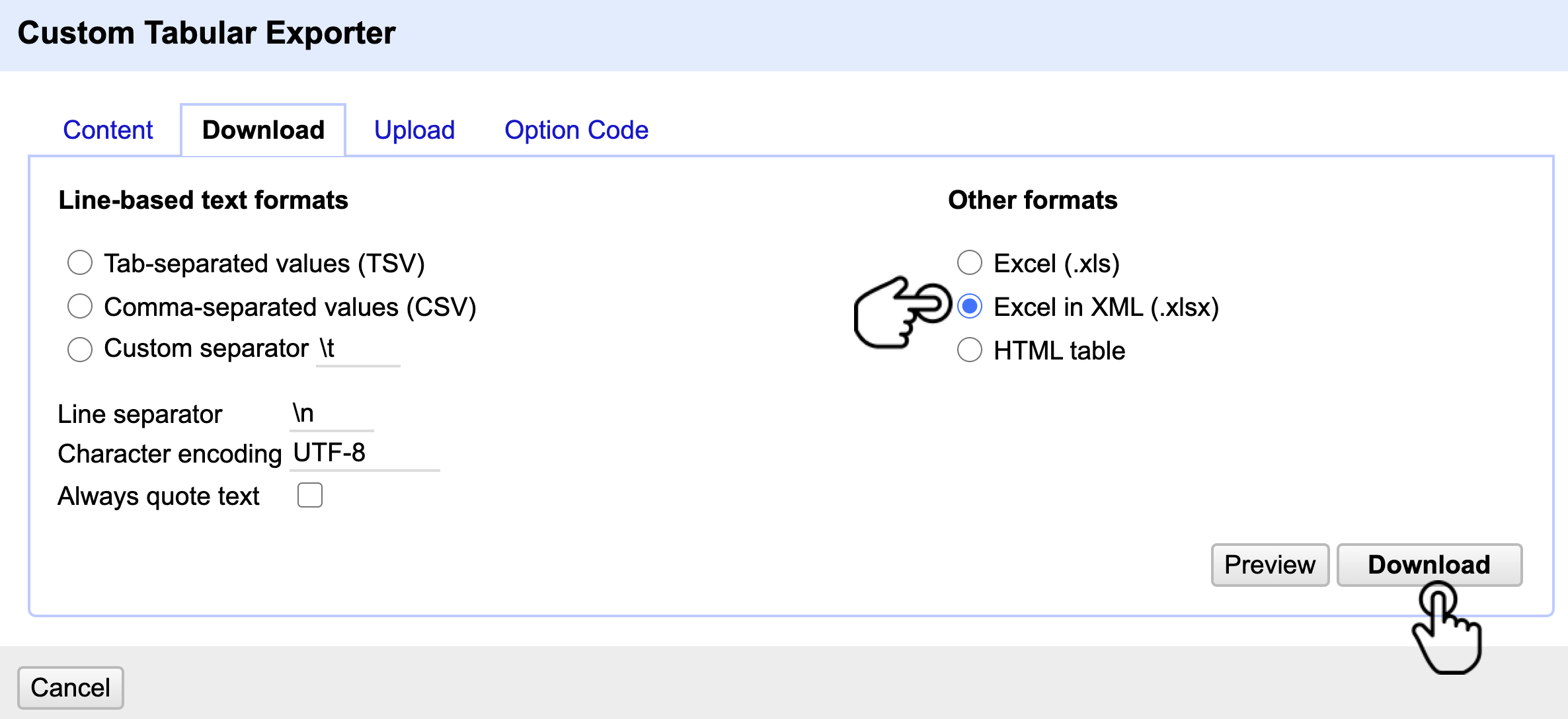
Figura 32. Selección del formato de descarga del conjunto de datos.
8.2 Exportar e importar un proyecto
OpenRefine también le ofrece la posibilidad de exportar el proyeco completo, esto permite descargar un archivo que contiene toda la información del proyecto (datos e histórico de cambios). Este archivo se puede utilizar para trabajar OpenRefine desde otro equipo. Para hacerlo diríjase a la esquina superior derecha y siga la ruta Export > OpenRefine project archive to file y guarde su archivo (Fig. 33).
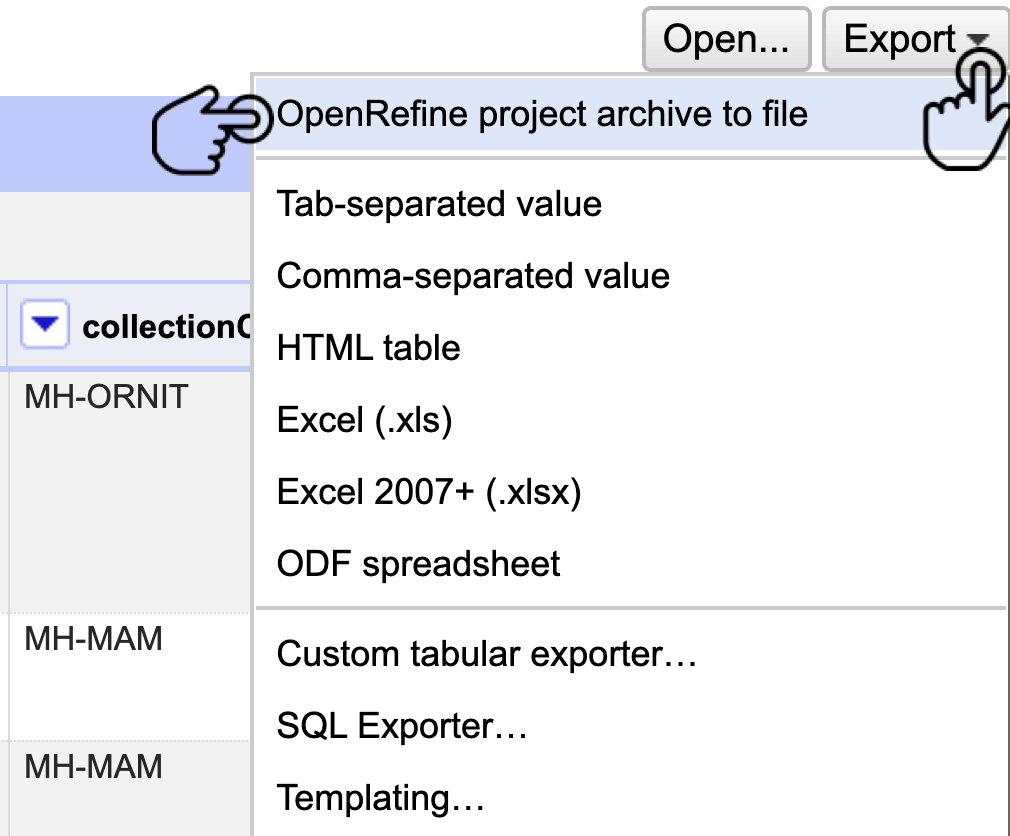
Figura 33. Exportación del proyecto.
Los proyectos exportados tienen la extensión”.openrefine.tar.gz” y no es necesario descomprimirlos para usarlos. Solamente abralos con el siguiente procedimiento.
Para importar el proyecto, abra OpenRefine y diríjase a la pestaña Import Project. Haga clic en Choose File y seleccione el archivo Datos_OR.openrefine.tar.gz y escoja la opción Import Project (Fig. 34).
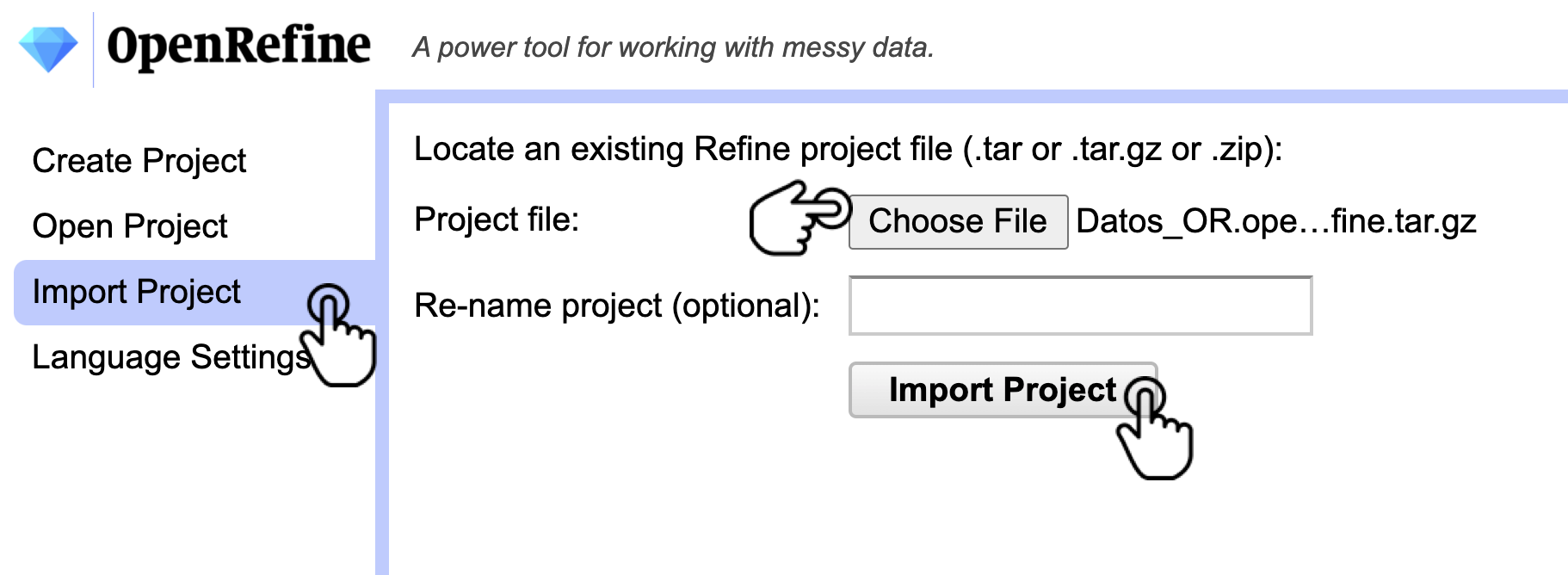
Figura 34. Importación de un proyecto en OpenRefine.
Paso 9 - Verificación del resultado
Compare sus resultados con el siguiente archivo validado según las definiciones del estándar, verifique en que acertó y que puede mejorar. Recuerde importarlo como un proyecto en OpenRefine. (Paso 8.2).
¿Qué diferencias encontró con sus resultados?
¡Felicitaciones! ![]() Has aprendido a utilizar OpenRefine para validar y limpiar tus datos sobre biodiversidad.
Has aprendido a utilizar OpenRefine para validar y limpiar tus datos sobre biodiversidad.
Atribución y uso de los laboratorios

La licencia CC-BY te permite usar, redistribuir y construir sobre estos contenidos libremente. ![]() Queremos que compartas estos laboratorios y que juntos logremos datos sobre biodiversidad de mejor calidad.
Queremos que compartas estos laboratorios y que juntos logremos datos sobre biodiversidad de mejor calidad.
Citación sugerida
Plata C., Ortíz R., Marentes E. (2021). Laboratorio de datos, Ciclo de formación. Consultado a través del SiB Colombia. Disponible en https://sib-colombia.github.io/Formacion/
Fuentes:
Verborgh, R., & De Wilde, M. (2013). Using OpenRefine. Packt Publishing Ltd.